MIT 6.S191 (2023): Convolutional Neural Networks

모든 정보와 슬라이드는 "MIT 6.S191 (2023): Convolutional Neural Networks"을 참고했다.
"To know what is where by looking"
What Computers "See"
📌 Images are Numbers
Tasks in Computer Vision : Computer Vision 이 하고자 하는 일
Regression : output variable이 continous value
Classification : output variable 이 class label. 특정 class에 속할 확률을 알아냄
High Level Feature Detection: 각 image category를 나타낼 수 있는 key feature들은 무엇인가
- Manual Feature Extraction: 관점이나 조명 이런 variation에 취약함, 당연히 manual 하게 한 거니까
🧐 Can we learn a hierarchy of features directly from the data instead of hand engineering?
이게 Neural Network가 잘하는 일이잖아!
Learning Visual Features
Fully Connected Neural Network를 사용하면?
- 공간 정보가 없어짐
- 너무 많은 parameter가 생겨버림
image에서의 특별한 내용인 spatial structure를 어떻게 보존할 수 없을까?
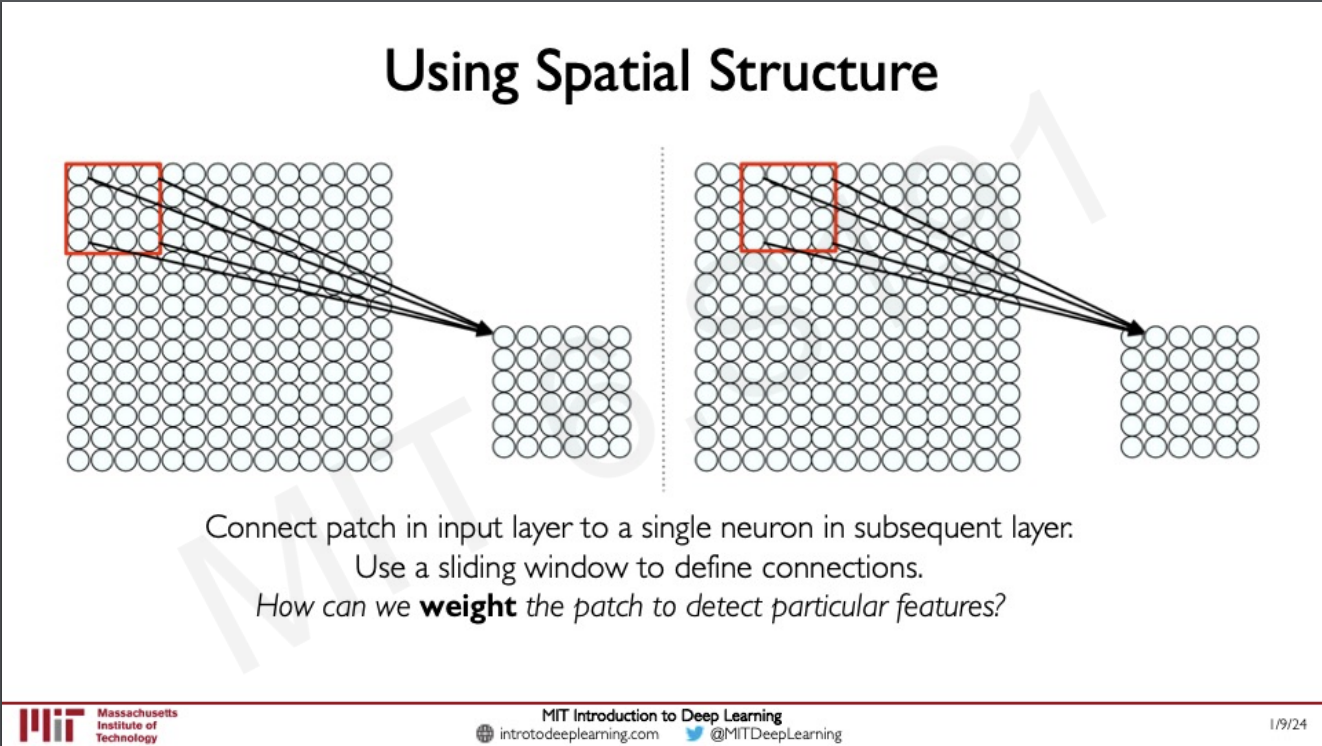
Neuron이 각 patch만 보게끔 하여 보존할 수 있다. 즉, 각 patch를 hidden layer의 neuron에 연결하는 것
Feature Extraction with Convolution
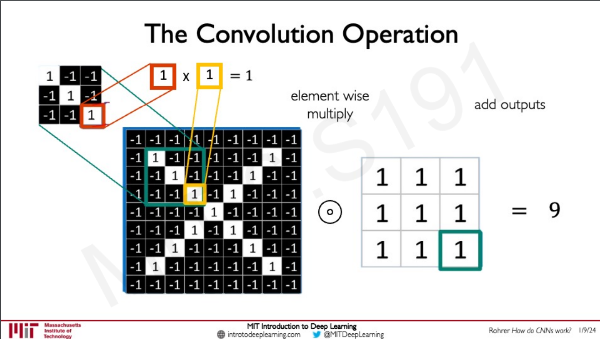
- local feature를 추출하기 위해 weight를 설정한다 (이것이 filter)
- 다양한 filter를 사용해 다양한 feature를 추출한다
- 각 filter의 parameter를 공간적으로 공유한다.

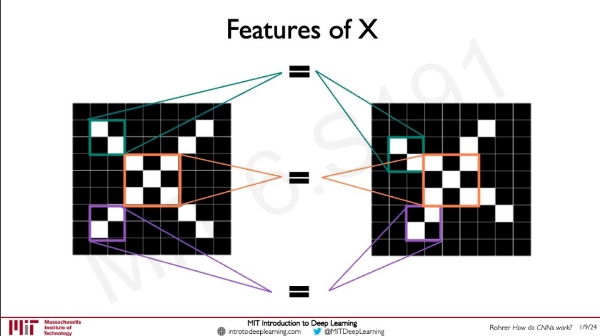
양쪽 그림 모두 X로 판별하고 싶다.
각 patch 별로 filter를 convolution 하면 얼마나 유사한 지 알아낼 수 있다.


결과적으로 모든 patch에 filter를 convolution 하면 feature를 extract 할 수 있다.
🧐 그렇다면 filter를 만들지 말고 learn 하면 어떨까
CNNs(Convolutional Nerual Networks)
- Convolution - Apply filters to generate feature maps
- Non-linearity - Often ReLU
- Pooling - Downsampling operation on each feature map
- Pooling의 의도 : Allows Network to deal with larger and larger scale images by progressively downscaling their size so that the filters can grow
Convolution
다음 layer에서는 더 큰 patch를 보게 됨
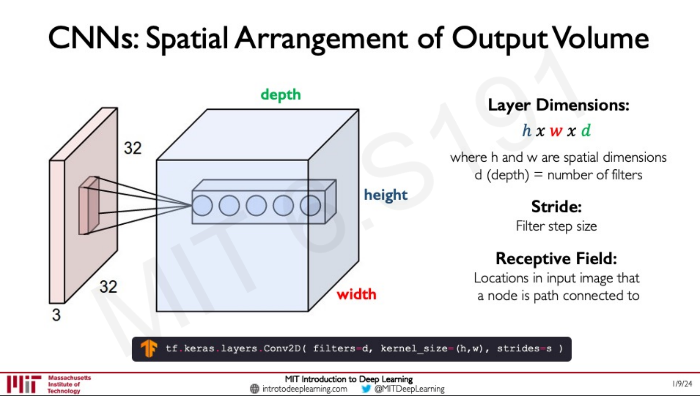
여러 개의 feature에 관심이 있다면 여러 개의 filter가 필요할 것임
그렇다면 output은 volume 형태이다. depth가 filter의 개수를 나타낸다.
Introducing Non-Linearity
ReLU : 음수인 값들은 다 0으로 처리
convolution 다음에 ReLU 적용
Pooling
max-pool : patch에서 제일 큰 값만 가져감
결과적으로 크기를 줄임
Result
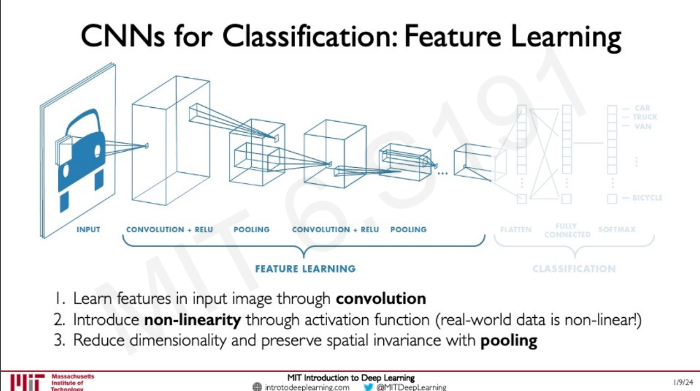
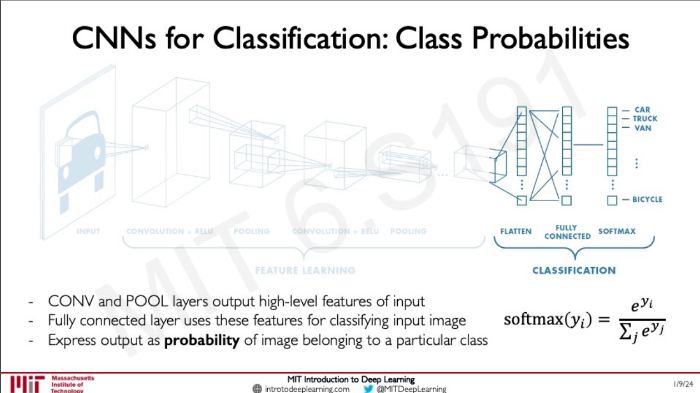
Convolution과 Pooling은 high level feature를 추출해 낸다.
Fully connected layer는 이 feature들을 이용해 input image를 분류한다.
output는 특정 class에 속할 확률을 나타낸다.
Application
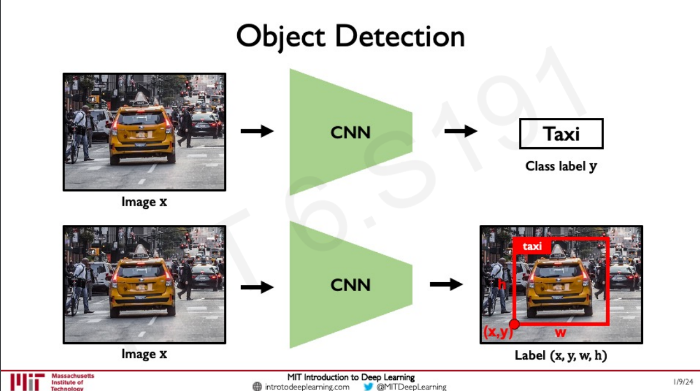
Feature Learning 부분의 유연성이 엄청 높아서 classification 말고, object detection 같이 하고 싶은 일과 이어 붙일 수 있다.
하지만 여러 개의 object을 detect 하고 싶은 경우에 random box로 알아내려고 하면 너무 scale, size가 크고, position 도 많다.
그래서
R-CNNs
Find regions that we think have objects. 있을 법한 자리를 찾는 것
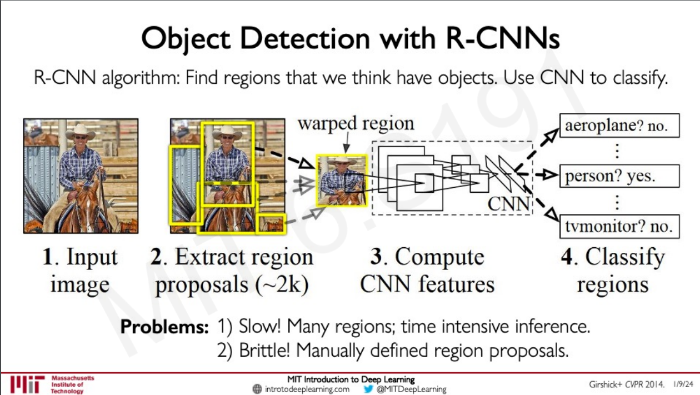
문제점: 너무 느리다(Many regions), 있을 법한 곳을 고르는 작업과 있는지 분류하는 작업이 서로 분리되어 있어 불안정하다.
Faster R-CNN
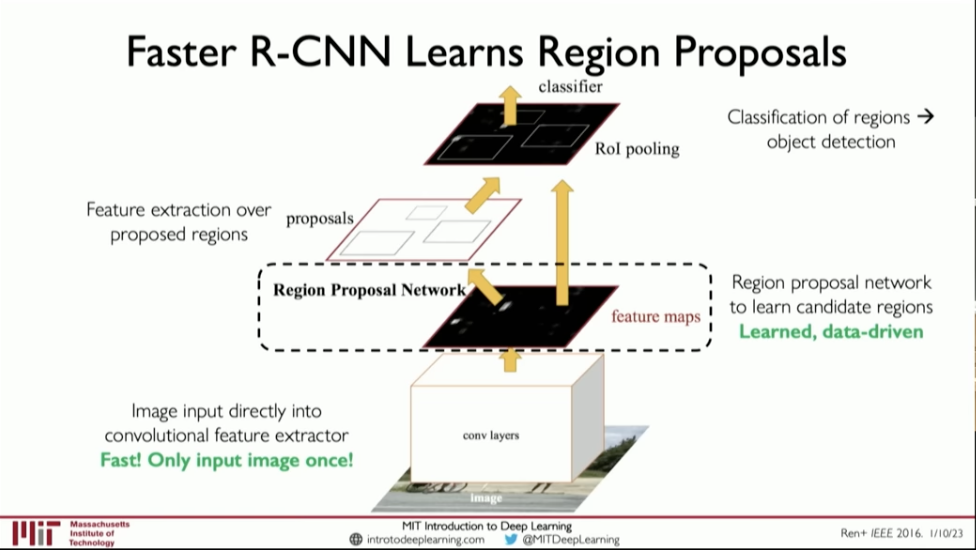
RNN은 Selective Search로 region을 찾아내는 반면 Faster R-CNN은 Region Proposal Network을 통해 알아낸다.
Semantic Segmentation: Fully Convolutional Networks
Classification을 하는 데 모든 pixel에 적용함, patch 이런 거 안 써!
✅각 pixel이 어떤 class인지 알아내기

© Alexander Amini and Ava Amini
MIT Introduction to Deep Learning
IntroToDeepLearning.com