

- What is cluster analysis
- Categories & Basic Concepts of Clustering
- Partitioning Methods
- Hierarchical Methods
⬇️ 여기부터
- Integration of Hierarchical & Distance-based Clustering
- Density Based Methods
- Summary
Integration of Hierarchical & Distance-based Clustering
hierarchical clustering 은 데이터가 커짐에 따라 너무 시간 복잡도가 커져버림, 차라리 K-means 쓰는 것이 나을 정도
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)
- Phase 1 : DB를 scan 하며 CF tree를 만든다.
- Phase 2 : 특정 clusering 을 사용해 leaf node를 CF-tree에 할당한다.
Scales linearly but, numeric data만 가능, 데이터 순서에 영향을 많이 받음
Clustering Feature $CF=(n, \vec{LS}, \vec{SS})$
n : Numer of data points
$LS: \sum_{i=1}^{n}\vec{X_i}$
$SS: \sum_{i=1}^{n}\vec{X_i^2}$
$\vec{x_0} = \frac{LS}{n}$
- CF는 height balanced tree ( root로부터 each leaf node까지 length 가 같음 )
- CF-tree
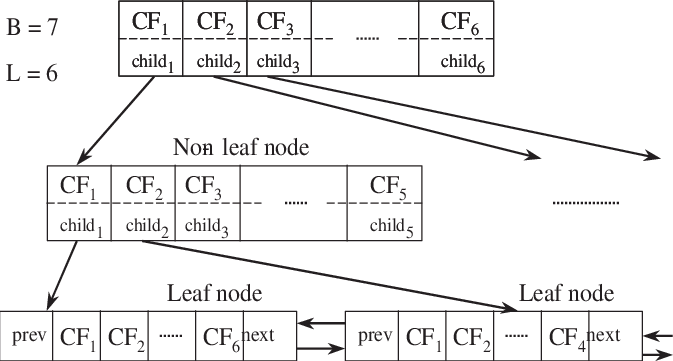
Branching factor(B, L) : B는 non-leaf node, L는 leaf node 영향받음, 각각 최댓값 나타낸 것
- d를 삽입할 때, 제일 가까운 거리에 있는 leaf node를 찾는다.
- 찾았다면
- node 안에 자리가 있다면 넣고 CF vector를 업데이트시킨다.
- 자리가 없고 branching factor에 의해 node를 새로 추가할 수 있다면 추가한다.
- 둘 다 할 수 없다면 node를 잘라 조건에 만족하도록 한다.
그럼 이제 BIRCH의 의미가 이해가 된다. CF tree는 balanced tree 여서 balanced이고 iteration , 노드를 넣을 때마다 언급한 과정을 반복한다. Reducing and Clustering, node가 들어올 때마다 clustering을 진행하고 각 값은 CF로 축약된다. Hierarchy, 이 모든 과정이 점점 cluster를 만들어가는 hierarchy clustering과 닮아 있다.
CHAMELEON
두 cluster는 interconnectivity와 closeness가 높을 때에만 merge 할 수 있다.
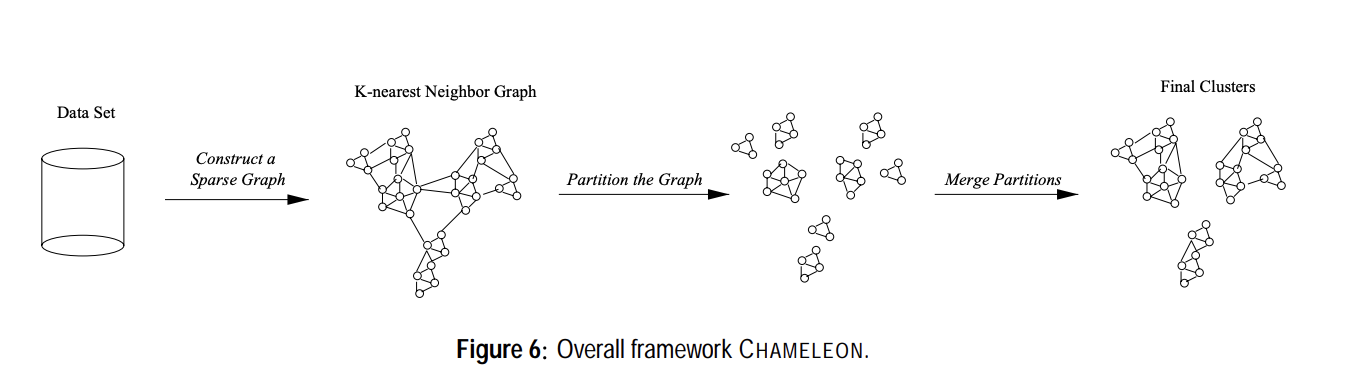
Partitioning :edge cut 이 최소화되도록 자른다. - library를 사용함
Merging :
Relative Inter-connectivity
(이 부분이 카멜레온 같음) $RI(C_i, C_j) = \frac {\left| EC_{C_i, C_j}\right|}{\frac {1}{2}({\left|EC_{C_i}\right|+\left|EC_{C_j}\right|})}$ 식은 이건데
cluster가 2개 있다면 그 두 개의 cluster를 잇는 edge cut를 구한다. 그 값이 큰 지 작은지 알기 위해서
각 cluster에서 그 cluster를 대충 반으로 나누는 edge cut을 구한다. 그 값을 나눠서 relative 하게 연결성을 확인한다.
주변의 cluster를 통해서 확인한다는 점에서 카멜레온과 비슷~~
Relative Closeness
평균값을 사용한다. 아까는 edgecut이었다면 이제는 edge의 평균값을 사용한다.
$RC(C_i, C_j) = \frac{\bar{S}_{EC{\{C_i, C_j\}}}}{\frac{\left| C_i\right|}{\left| C_i\right| + \left| C_j\right|}\bar{S}_{EC_{C_i}}+\frac{\left| C_j\right|}{\left| C_i\right| + \left| C_j\right|}\bar{S}_{EC_{C_j}}}$
최종적으로 RI와 RC값을 곱한다.
Density-Based Methods
distance 쓰지 말고! density 쓰자!
DBSCAN : Density Based Clustering Methods
$\epsilon$ : p 점으로부터의 neighbor인 노드를 선별하기 위한 거리
MinPts : neighborhood의 최소 포인트 수 - "high" 하다는 것은 적어도 MinPts 이상의 포인트가 있다는 것을 의미한다.
Density - Reachable
- Directly Density - Reachable
- q에서 p로 directly density reachable 하려면 p가 core object여야 하고 q가 neighborhood여야 한다.
- Indirectly Density Reachable
- 만약 q->p, p->k, k-> h가 차례로 directly density reachable 하다면, q->h은 indirectly density reachable 하다.
DBSCAN
DBSCAN은 자료를 사이에 불 지른 거랑 비슷하다, 가까이 탈 것이 있어야 계속 탈 수 있다.
알고리즘
- 모든 DB는 undefined라고 label를 달고 시작한다.
- undefined라고 label 된 포인트 중 그 근처 neighbor 포인트를 센다.
- 만약 MinPts 보다 작으면 Noise라고 라벨링 하고 다시 2로 간다.
- 작지 않다면 새로운 cluster label를 할당하고 거기에 neighbor 포인트들을 넣는다.
- 이제 neighbor를 확장할 거다. 각 neighbor 포인트를 순환하며 그 포인트와 가까운 포인트들을 다 cluster에 할당한다.
장점 : 어떤 모양이든 가능하다, cluster의 개수가 저절로 정해진다, noise랑 outlier를 구분해 낼 수 있다.
단점 : 입실론으로 무엇을 주냐에 따라 결과가 많이 달라진다.
OPTICS
extension from DBSCAN
Ordering Points To Identify the Clustering Structure
어떤 입실론 값을 설정해야 할까
core-dist : P를 core로 만드는 가장 작은 값
reachability-dist : 어떤 한 점으로부터의 거리와 core-dist 사이의 max 값
시각화하면 valleys를 나타냄, 더 깊을수록 더 밀집도가 높다.
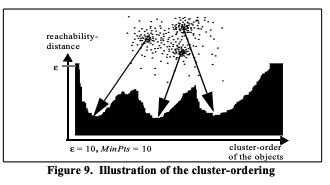
이 결과를 보고 어떤 입실론 값을 쓸지 정할 수 있음
'데이터 사이언스' 카테고리의 다른 글
| Recommender Systems (0) | 2024.06.17 |
|---|---|
| Clustering 후반부 - 2단계 (2) | 2024.06.17 |
| Getting to know Your Data & Data preprocessing (1) | 2024.06.17 |
| Clustering 전반부 - 3단계 (0) | 2024.06.10 |
| Clustering 전반부 - 2단계 (2) | 2024.06.09 |