
728x90

모든 정보와 슬라이드는 "MIT 6.S191 (2023): Recurrent Neural Networks, Transformers, and Attention"을 참고했다.
RNN의 limitation을 복습하면
- Encoding bottleneck(모든 정보가 maintain 되었는지 보장하기 어려움)
- Slow, no parallelization
- Not long memory (엄청 큰 sequnce data는 다루지 못함...
였다. 이것을 해결하기 위해 생각해 볼 수 있는 방법들이 있는데,
Feature vector를 하나로 만들어서 한꺼번에 처리하는 방법을 생각해 볼 수 있지만
순서를 보존하지 않고, 크기에 영향을 받는다.
Attention is All You Need
Intuition - attending to the most important parts of an input
한 번에 처리하는 것이 목적이다. 그 방법은
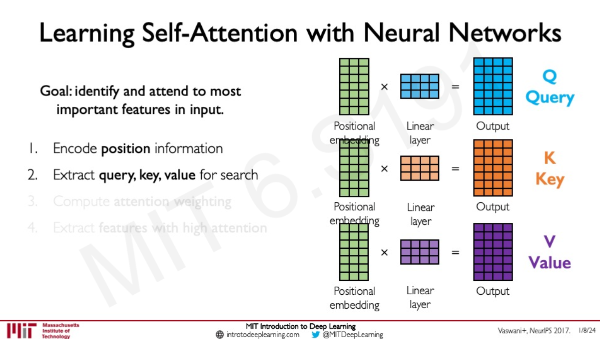

각각의 위치를 encode 한 행렬에 각각 다른 NN layer를 통해 query, key, value 순으로 extract 한다.
그 후에 attention score을 통해 어떤 값들이 중요한지 알아낸다.

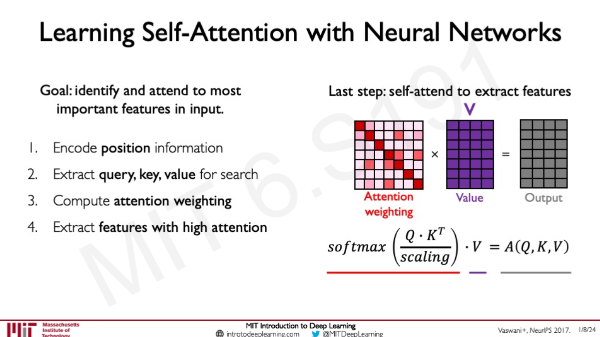
Query와 Key 값의 유사도를 비교해 Attention weighting을 얻고 그 값을 softmax 취한 후 Value에 곱한다.
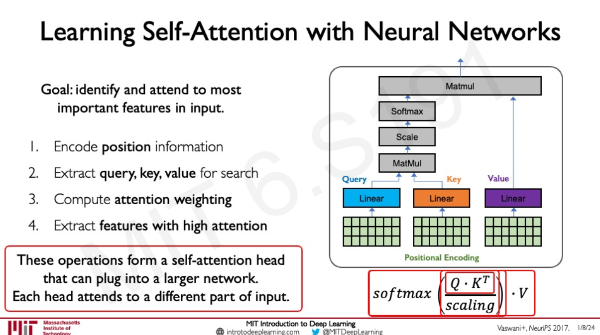
결론적으로 이 슬라이드처럼 진행되는데 또 다른 활용은 집중하고 싶은 부분에 따라 이 self-attention head를 여러 개 사용할 수 있다는 것이다.
Self-attention to model sequences without recurrence
가 핵심일 거 같다.
+ Attention is All you Need 꼭 읽어봐야지...
© Alexander Amini and Ava Amini
MIT Introduction to Deep Learning
IntroToDeepLearning.com
728x90
'딥러닝' 카테고리의 다른 글
| Language Deep Learning 찍먹 (2) | 2024.06.13 |
|---|---|
| MIT 6.S191 (2023): Convolutional Neural Networks (2) | 2024.06.07 |
| MIT 6.S191 (2023): Recurrent Neural Networks, Transformers, and Attention (~44:50 RNN, LSTM) (0) | 2024.06.06 |
| MIT 6.S191 (2023): Deep Generative Modeling (41:25~ GAN) (0) | 2024.06.06 |
| MIT 6.S191 (2023): Deep Generative Modeling (~41:25 VAE) (1) | 2024.06.06 |