

Language에 대한 deep learning 내용들을 아주 얇게 찍먹해 보겠다.
NLP ( Natural Language Processing) - 자연어 처리
- text 분류, 번역, 자막 자동 생성, image captioning 등등등
text data를 다룰 때 문제점
- 문서들의 길이가 매우 다양해 structured로 만들기 어렵다.
- TF-IDF 사용하기 로 해결 가능
- one - hot encoding 으로 사용할 수 있는 데, 차원이 너무 커지고 단어들 사이의 거리를 알 수 없음
- word embedding 사용하자 - 더 낮은 차원으로 보내기
- test 때 못봤던 단어를 볼 수 도 있다.
- 모르면 unknown이라고 하기
- TF-IDF 사용하기 로 해결 가능
BOW, TF, DF, IDF, TFIDF
BOW : 특정 단어가 특정 문서에 얼만큼 등장 했냐 (벡터)
TF : 특정 단어가 특정 문서에 얼만큼 등장했냐 (행렬) - BOW를 이어 붙인 것임
DF : 특정 단어를 가진 문서가 몇개냐 - TF에 row 의 non-zero 갯수
$ IDF_{i} := log(\frac{N}{1+DF_{i}})$
$TFIDF_{in}:=log(TF_{in}+1)\times IDF_{i}$
BUT. TF-IDF는 의미적으로 비슷한 단어들이 서로 가깝게 위치 하지 않을 수 있음! 그래서 word embedding 을 해야함.
Word Emdedding
= semantic 하게 비슷한 단어들은 비슷한 context에서 등장한다.
PGM( Probabilistic Graphical Model )
$Y_{i}\perp Y_{pred(i)} | Ypa_{i}$
$Y_{i}$의 parent가 주어졌을 때 parent의 parent인 predecessors 와는 독립이여서 곱으로 나타낼 수 있다.
$p(Y_{1:V}) = \prod_{i=1}^{V}[(Y_{i}|Y_{pa(i)})]$
parent에 대해서 중요하다. 위상 정렬이랑 연관해서 생각하면 될듯
Word2vec
- CBOW : 주변 단어들로부터 중간 단어들 예측하기
- skipgram : 중간 단어들로부터 주변 단어들 예측하기
Recurrent NNs (RNNs)
- Vec2seq
- Seq2Vec
- Seq2Seq
를 언급하기에 앞서
Markov Model
미래 state는 오직 현재 state에만 영향을 받는다. 그 전 state에는 영향을 받지 않음
이라고 하는 것인데 너무 inductive bias가 쎄다..
그래서 RNN 이 나온것임!
MIT 6.S191 (2023): Recurrent Neural Networks, Transformers, and Attention (~44:50 RNN, LSTM)
모든 정보와 슬라이드는 "MIT 6.S191 (2023): Recurrent Neural Networks, Transformers, and Attention"을 참고했다.MIT 6.S191 (2023): Recurrent Neural Networks, Transformers, and AttentionSequence Modeling 앞으로 나오는 ML을 잘 이해하
daily-programming-til.tistory.com
여기에서 좀 더 자세히 알아봤었다.
Vec2Seq 는 vector에서 sequence를 얻는 거다. image를 주고 caption 달게 하는 것 을 생각할 수 있는데,
$p(y_{t} | h_{t})=Cat(y_{t} | softmax(W'h_{t})) = \phi (W[x;y_{t};h_{t}])$ x, y, h에 대한 weight는 서로 다르다는 것 알아두기.
Seq2Vec 는 $h_{t} = \phi (W[x_{t};h_{t-1}])$, $p(y|x_{1:T})=Cat(y|softmax(W'h_{T}))$ Weight에 이전 y가 없다는 것 알아두기
Seq2Seq 는 $h_{t} = \phi (W[x_{t};h_{t-1}])$, $p(y|h_{T})=Cat(y_{t}|softmax(W'h_{t}))$ h값을 다 구한 T가 아니라 각각 t다.
Teacher Forcing
학습을 빠르게 하는 방법으로 right shift 한 후 예측한 값이 틀리면 무시하고 ground truth를 넣어주는 것이다.
근데 RNN은 점점 시간이 지날 수록 앞 내용을 까먹는다, 그리고 vanishing gradient 문제가 있다.
그래서 나온게 GRU, LSTM 인데 뭐.. attention이 씹어먹은듯
Transformer
Attention : 순서 개념을 없앤다. 바로 전에 것에만 의존하다는 것은 너무 큰 bias 였음
query와 key의 유사도를 구한다. 미분이 되도록 softmax를 취해준다. value와 곱해준다.
Attention Weight
$A = (\alpha _{ij})$
$\alpha_{ij}\equiv [\alpha(q_{i}, k_{1:N})]_{j}$
$:= softmax_{j}(a(q_{i},k_{1}), a(q_{i},k_{2}), \cdots ,a(q_{i},k_{N}))$
즉 뭔말이냐 하면 query i 에 대하여 모든 key 값과의 유사도를 구하는 것이다. 그리고 normalize 해주는 거다.
다음
유사도를 어떻게 구하냐
$a(q, k) = g^{T}k / \sqrt[]{d_{k}}$ 이렇게 구한다.
그래서 바로 앞에 적었던 식이랑 합쳐서 간단하게(?) 나타내면
$\alpha_{i*} = softmax([q_{i}^{T}k_{1}, q_{i}^{T}k_{1}, \cdots , q_{i}^{T}k_{1}]/\sqrt{d_{k}})$
그리하여
$head=Attention(QW^{Q}, KW^{K}, VW^{V})= \phi _{s}(QW^{Q}W^{KT}K^{T} / \sqrt{d_k})VW^{V}$
Multi-head Attention
MHA(Q, K, V) = Concat(head1, head2, head3, ..., headh) W
attention은 input 과 output의 차원이 같다.
N X d 가 input이면 Q가 N X dk 고 K가 N X dk 여서 곱하면 N X N이 되고 value 도 N X dk 여서 결국 N X d
여기까지가 encoder 부분이었고, 이제는 decoder부분이다.
여기서 K, V는 encoder에서 들어오는데 state 또는 memory라고 불린다.
Positional Encoding :Attnetion 은 순서를 그냥 다 무시해 버렸는데 너무 inductive biasfmf 줄여 버려서, word embedding 에 position을 더해주는 정도 같은게 있다.
Add & Norm : layer Normalize - layer 값이 크게 변하게 하는 것을 방지해 빠르게 학습
Masked MHA - decoder 쪽
입력값을 예측할때 미래 시점 입력값까지 참고하지 않도록 하는 것
head i 는 head i - 1번째 것까지만 참고하셈! 그 이후 값은 마이너스 무한대로 보내 버린다음에 Softmax 취할때 0으로 바뀌어 버림
Vision Tranformer
엥~ vision 에도 해보자
input을 patch 별로 잘라서 Position embedding 해서 넣음
Efficient Transformer - 연산 순서를 바꿔 효율 높이기
LLM
여기서부터는 수식없이 거의 개념만 정리할 것이다...
ELMo : Embedding from Language Model
두개의 RNN LM을 사용해서 하나는 왼쪽에서 오른쪽으로 하나는 오른쪽에서 왼쪽으로 가게한 다음 hidden state을 합해 각 단어의 embedding 결정
BERT(Bidirectional Encoder Representation from Transformers)
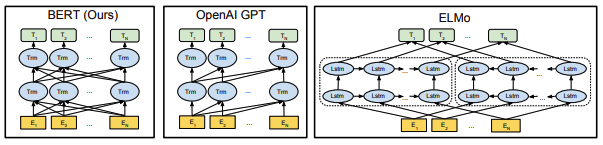
encoder 만 사용한다. random binary mask를 사용하는데, 모델은 문맥에서 그 mask된 단어를 예측해야한다.
fill in the blank! 그리고 NSP(next sentence prediction) 방식도 있다. 다음 문장으로 옳은 것은? 이런거 풀면서 학습
GPT (Generative Pre-trained Transformer)
GPT-3 부터 in-context 기능
ChatGPT : + RLHF(RL from Human Feedback)
뒤로 갈 수록 매우 얼렁뚱땅하게 넘어갔는데 시험끝나고 더 자세히 알아보..겠다!