
728x90

데이터의 양이 적을 때 쉽게 overfit 될 수 있는 문제를 어떻게 해결해야 하는가?
Data Augmentation
- random crop
- zoom
- 뒤집기
Transfer Learning
데이터가 많은 task(pre-training)한 내용을 기반으로 데이터가 별로 없는 task(fine-tuning)하기
source data랑 target data가 비슷해야 함
단순히 마지막 layer를 잘라내 버리고 원하는 task 하도록 붙여버림
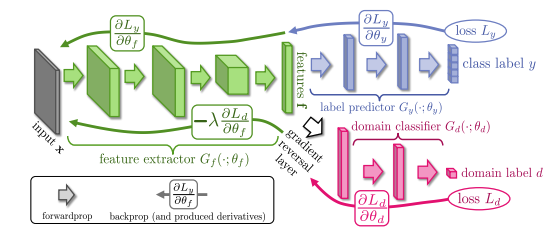
Domain Adaptation
서로 다른 Domain의 input을 넣는 데 output은 같은 domain이여서 "dual" of transfer learning
그니까 domiain adversarial learning을 해야하는 데 source에서 오는 input인지, target에서 오는 input인지 구별하지 못하도록 속이는 것이다. 이를 통해 두 domain 사이의 공통 feature를 찾아낼 수 있다. 하나는 속이고, 하나는 뭔가 뭔지 알아내고 싶고.
Semi-Supervised Learning
label 되지 않은 데이터가 있을 때 활용
Active Learning
데이터가 너무 없을 경우에
예를 들어, learning rate 를 어떻게 할지 모를때 한번 한번이 너무 오래 걸려서 빨리 최대한 적은 query를 통해 찾아내려고 하는 것
근데 제대로 이해 못했음...
Meta Learning (learning to learn)
MAML : task의 starting point를 학습하는 것
와 여기 부분은 너무 어렵다...
728x90
'딥러닝' 카테고리의 다른 글
| VAEs, GAN, Diffusion Model (1) | 2024.06.14 |
|---|---|
| Self Supervised Learning 찍먹 (1) | 2024.06.13 |
| Deep Learning 기본 내용들 (Bayes 정리, Maximum Likelihood, prior, Maximum posterior) (2) | 2024.06.13 |
| Language Deep Learning 찍먹 (2) | 2024.06.13 |
| MIT 6.S191 (2023): Convolutional Neural Networks (2) | 2024.06.07 |