

UNLABELED DATA
세상에는 Label이 없는 데이터가 훨씬 많다. 이걸로 학습하는 게 진짜임
Self Supervised Learning
Imputation Tasks
input을 두 부분으로 나눠서 하나는 가리고 (hidden) 하나는 보이게 해서 hidden 부분을 예측하게 하는 것
Visible 한 부분으로 hidden을 예측 할 수 있다는 inductive bias가 존재함
ex) fill-in-the-blank 같은것(BERT)
Proxy Tasks
예를 들어 사진을 돌려서 준다음에 몇도가 돌아갔는 지 예측하도록 하는 것
target을 잘 나타내는 representation을 배우는 것이 목적
Contrastive Tasks
Learning Distance Metrices

label이 없는 데이터 간 거리를 나타내는 방법들
이제 SimCLR가 더 잘 이해된다.
SimCLR
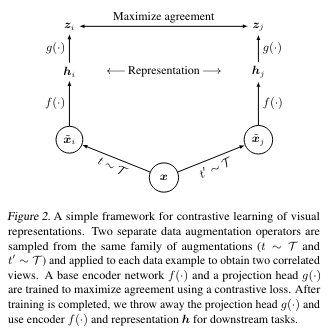
이제 수식을 잘 이해할 수 있는데,
$sim(z_{i}, z_{j}) = cos(z_{i}, z_{j})$ 우선 z 사이의 유사도는 이렇게 구할 수 있다.
그 다음에 loss 를 구하기 위해 agree를 구하는데
$agree_{i, j}=\frac{exp(sim(z_{i}z_{j}/\tau ))}{\sum_{k-1}^{2N}1(k\neq i)exp(sim(z_{i}z_{k})/\tau )}$
그니까 가능한 모든 z와의 거리에서 i, j일때의 유사도를 확률적으로 나타낸 것이다.
이것을 -log을 통해 negative log likelihood 로 minimize한다.
CLIP
$L_{ij}=cos(I_{i}, T_{j})$
image i 에 대해 text T가 유사한 정도를 나타낸다.
loss function 은
$L=\sum_{i}^{}-log[softmax(L_{i,:})]_{i} + \sum_{j}^{}-log[softmax(L_{:,j})]_{j}$
로 답이 image i일 확률과 text j일 확률을 높여야한다.
그래서 train 이후에 어떻게 classify 하냐
$p(y_{k}|x)=softmax(cos(I, T_{1:K}))_{k}$
제일 text와 image의 유사도가 높은 것을 고른다.
'딥러닝' 카테고리의 다른 글
| VAEs, GAN, Diffusion Model (1) | 2024.06.14 |
|---|---|
| Learning Fewer Labeled Examples (0) | 2024.06.13 |
| Deep Learning 기본 내용들 (Bayes 정리, Maximum Likelihood, prior, Maximum posterior) (2) | 2024.06.13 |
| Language Deep Learning 찍먹 (2) | 2024.06.13 |
| MIT 6.S191 (2023): Convolutional Neural Networks (2) | 2024.06.07 |